
Build an AI image catalogue! - Claude 3 Haiku
Building an Intelligent Photo Album with AWS
If you’re into your Machine Learning/Artificial Intelligence/Generative AI and have been living under a rock, it may be news to you that Anthropic have now released their latest version of the Claude Large Language Model (LLM), which they have predictively named, Claude 3. But what’s not so predictable is that not only is this the third generation of Claude, but there are also three different variations of Claude.
In this post, we’re going to explore the creation of a basic, serverless, image cataloguing application using Claude 3 and explore how it enhances the functionality of our AI photo album application. Powered by Amazon Bedrock, this application leverages the poetic prowess of Claude 3 Haiku to provide insightful summaries of uploaded images.

In today’s digital era, our memories are often immortalized through the lens of a camera, capturing moments that evoke a myriad of emotions. As our photo collections grow, organizing and making sense of these images can become a daunting task. However, with the emergence of artificial intelligence (AI) and cloud computing, we now have the opportunity to create intelligent solutions that automate and enrich the photo management process.
Announcing Claude 3
“The next generation of Claude: A new standard for intelligence” - https://www.anthropic.com/news/claude-3-family
When Claude 3 was announced they came up with not just one new model, but three:
Haiku (Available on Amazon Bedrock) Sonnet (Available on Amazon Bedrock) Opus (Coming soon to your favourite AI provider starting with B… and ending in rock)
Now whilst I write this in celebration of the Claude 3 family, I’m not going to go into all the differing benchmark charts as I’m sure you’ve already seen, however, the links and resources in this post should provide the benchmarks you seek if this is something you’re interested in.
What really got my attention was the overall impact that the whole Claude 3 family has on the LLM landscape. Bold strokes of improvement across all three variances including;
- Near-instant results
- Strong vision capabilities
- Fewer refusals
- Improved accuracy
- Long context and near-perfect recall
- Responsible design
- Easier to use
Source: https://www.anthropic.com/news/claude-3-family
What got my attention the most was the claim of “Strong vision capabilities”. How strong? That’s something I wanted to test out.
I originally started writing this little project about 2 weeks before the release of Claude 3 Haiku, using Claude 3 Sonnet. The appeal was that Claude 3 Sonnet was offering unmatched vision capabilities.
“The Claude 3 models have sophisticated vision capabilities on par with other leading models. They can process a wide range of visual formats, including photos, charts, graphs and technical diagrams. We’re particularly excited to provide this new modality to our enterprise customers, some of whom have up to 50% of their knowledge bases encoded in various formats such as PDFs, flowcharts, or presentation slides.”
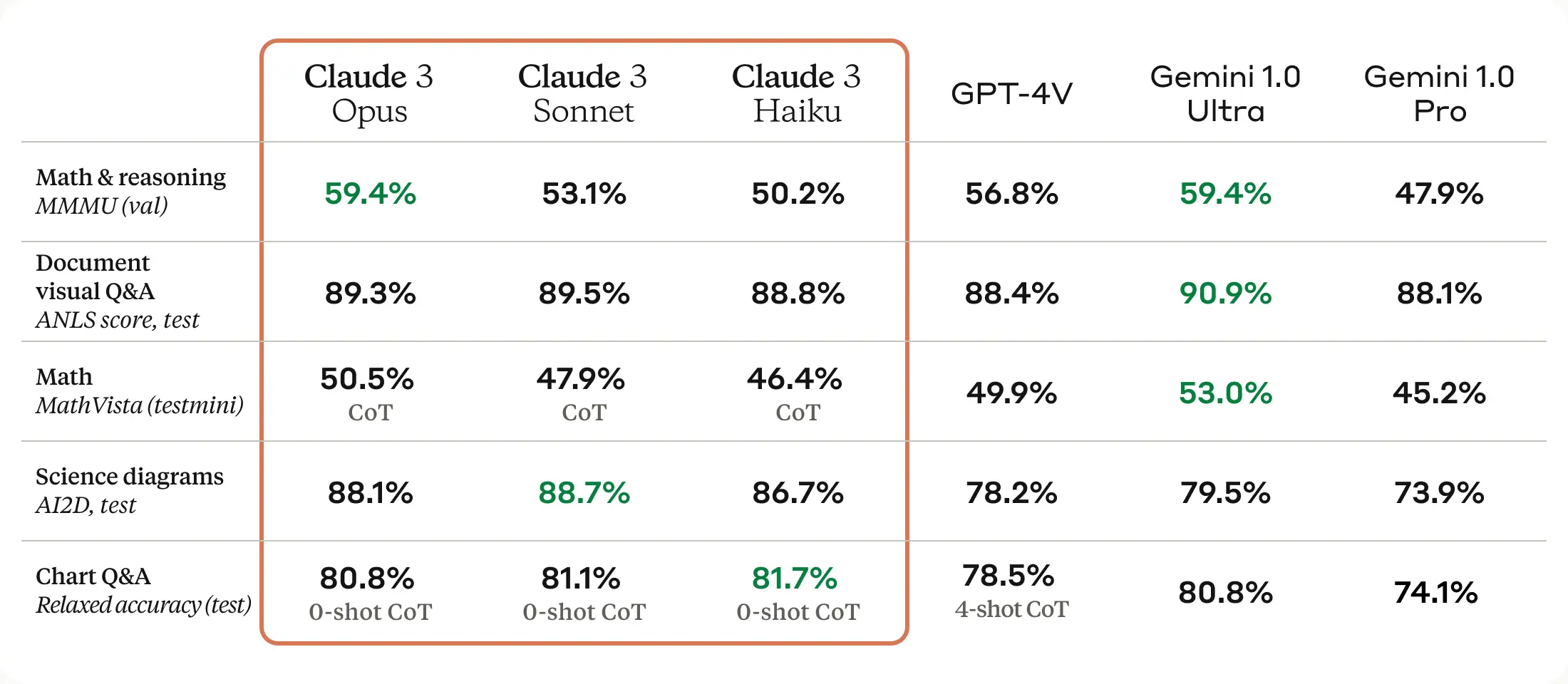
(OK I caved in and put a benchmark chart in - worth it though!)
Exploring Claude 3 Haiku
“Claude 3 Haiku: our fastest model yet” - https://www.anthropic.com/news/claude-3-haiku
The moment Haiku was released, my colleagues at the other end of the work meeting I was attending at the time were greeted with a physical whoop of joy. I was already excited by Claude 3 sonnet so having the next in the generation arrive was like Christmas had come early.
I also knew this meant that I could change my large language model from Sonnet to Haiku.
The benefits it provided to my proof of concept were:
- The fastest model in the Claude 3 family
- The most cost-effective model in the Claude 3 family.
This means a lot, especially in a proof of concept like this. This gives us the speed of execution to develop fast, fail fast and iterate on solutions a lot quicker. It also means that we’re able to control the costs of the application.
“Speed is essential for our enterprise users who need to quickly analyze large datasets and generate timely output for tasks like customer support. Claude 3 Haiku is three times faster than its peers for the vast majority of workloads, processing 21K tokens (~30 pages) per second for prompts under 32K tokens [1]. It also generates swift output, enabling responsive, engaging chat experiences and the execution of many small tasks in tandem.”
This speed also means the ability to analyze documents at a much faster rate than ever with a faster recall of information.
In our use case, we want to visualize our images by using descriptive language to help create a catalogue of images with a summary and to also have it provide a category for the image.
This can create powerful use cases such as making art more accessible for the blind or improve operational overhead in managing catalogs of stock images in a creative studio.
Let’s start building!
By the end of this post, I hope to have demonstrated:
- Seamlessly integrate Claude 3 Haiku into a photo album app
- Calling Amazon Bedrock from a serverless application
- Basic Architecture that is needed to achieve this.
- Some lessons learned with Prompt Engineering
The “Lego Bricks”
The basic architecture that we’re going to build looks something like this:
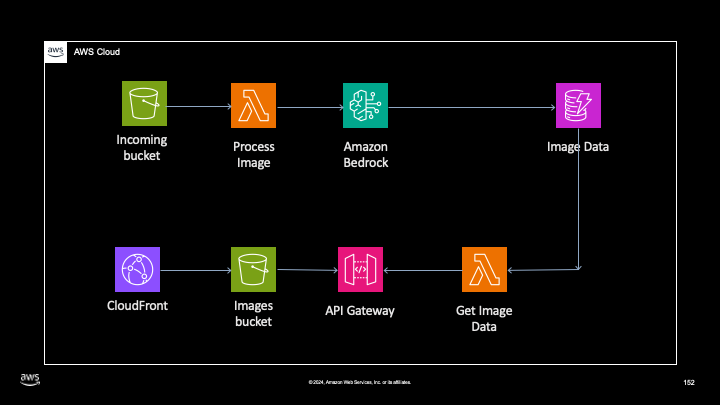
I liken AWS Services to Lego bricks. There are many of them and when put together in varying combinations, they can make many unique different builds. In this build, we’ll be using:
Amazon S3
- To receive images and send them to be processed using S3 Events
- To store and host processed images and a static-hosted HTML page API Gateway
- To accept a GET request from a static-hosted HTML page AWS Lambda
- To receive the S3 event and process the image
- To accept a GET request and provide the user with the image data Amazon Bedrock
- To leverage Calude 3 and provide an AI-generated summary and category Amazon DynamoDB
- To store the information generated by Claude 3 / Amazon Bedrock
I’ve utilised the AWS Serverless Application Model (SAM) framework to help build and deploy this as well to keep things as easy as possible.
“SAM and Bedrock? Surely not?!?” - Remember, Amazon Bedrock is a serverless service and can be called by an API or an SDK. The power is yours to call Bedrock any way you want to.
And last but not least, our language of choice. Python for our AWS Lambda functions and there’s a small sprinkling of old-school Javascript to assist the front-end HTML.
If you’re keen to get this setup yourself feel free to browse the repo and get started yourself - https://github.com/alanblockley/bedrock-haiku-image-catalog
Otherwise, for more explanation, keep reading.
Prompt Engineering - No such thing as too much
When writing this little experiment I started with a very typical MVP style approach. Get something working. We’ve all been there, right? But in this process, I fell victim to also shirking on my prompt for Claude 3. My original prompt was something like
“Provide me a summary of this image and give it a short category”.
In my defence, it worked. But as any good builder/coder/developer, I read the documentation… actually, no I didn’t… Have you read IKEA instructions, I’ve been burnt for life! But instead, I sought out a peer review from a very good friend of mine. He swiftly explained that this was a bad prompt. But I didn’t get it. Yes, I’ve done ML/AI/PartyRock/Gen AI stuff but I’ve never really had to write anything in anger until now.
The explanation of why this is a bad prompt can be complex. To make it easier to understand, let’s think of it in human terms, after all this is an emulation of human intelligence. In your prompt you need to allow for:
- Time for the model to think about what it’s doing - When we are thinking about something or trying to work on something, we generally think it through 3 or 4 times maybe, sometimes we’ll jot down some notes as well.
- Structure your output - Claude likes XML tags, so maybe have Claude structure it’s output. Ask it to put it’s thinking into XML tags such as
<SCRATCHPAD>or<NOTES>, closing them respectively. Then have it put the output of value, your output, into another XML tag such as<OUTPUT></OUTPUT> - The more detail the better. Assume you’re explaining this task for the first time to a trainee. If a trainee runs this task for the first time and gets it wrong, you didn’t explain it well enough and Claude definitely won’t get it right. Give it a purpose or a role. It’s not good to expect a toaster to dispense ice. So ensure that your model is given a contextual purpose to work to. * This will help make your answers more accurate.
Whilst all of these actions will help find the accuracy you need in your AI tasks, they’ll also make things more consistent as well. With this advice, my prompt ended up taking up 34 lines and told a story to the model, not just a quick 1 line action that could be interpreted vaguely. Have a play with it and see what you think.
And don’t forget a little bit of logic in your code to help extract the data from the XML tags. I’ve included a Python example in my repo.
The Lambda Functions
In our architecture, we’ve detailed two functions. One that processes images and one that retrieves the stored data.
For the sake of simplicity, there’s a third function, not detailed in the diagram, which takes the image and copies it to the image store but also renames the image to a random, unique UUID. This is to help indexing and also removes any bias from the AI generation of image data. The model then has no concept of image name. You could also add MIME checking, AV scanning and other checks here and also utilise this bucket to receive from anywhere such as AWS Transfer Family or a web front end via Presigned URLs.
I’ve included the functions in a public repository for you to play with - https://github.com/alanblockley/bedrock-haiku-image-catalog
For the sake of making this an interesting read, I’ve only included a copy/paste of the function that calls Amazon Bedrock. This function performs the following:
- Decode Image Name: Extracts the name of the uploaded image from the S3 event and removes any obfuscation caused by URL formatting of the name.
- Retrieve Image Type: Determines the MIME type of the uploaded image using the S3 object key.
- Retrieve Image Data: Fetches the image data from the designated S3 bucket.
- Encode Image Data: Converts the image data to a base64-encoded string for processing by the Claude 3 Haiku model.
- Generate Summary: Utilizes the Claude 3 Haiku model to produce a summary of the image content.
- Extract Summary: Parses the response from the Claude 3 Haiku model to extract the generated summary.
- Store Summary in DynamoDB: Stores the extracted summary along with relevant image details (e.g., object ID) in a DynamoDB table for future retrieval.
This lambda function will also handle the streaming output that Bedrock provides and format it in such a way that it can be inserted into a DynamoDB table.
Also note, that I asked for structured data from the model. So when Claude presents me with this data, it’s creating a JSON string within the XML tags which I then use to continue processing the data.
Summarise Image - Code
import os
import json
import boto3
import base64
import urllib.parse
from botocore.exceptions import ClientError
IMAGE_TABLE = os.environ['IMAGE_TABLE']
IMAGE_BUCKET = os.environ['IMAGE_BUCKET']
s3 = boto3.client('s3')
dynamodb = boto3.resource('dynamodb')
bedrock_runtime = boto3.client('bedrock-runtime')
def extract_substring(text, trigger_str, end_str):
# Find string between two values (Thanks for this Mike!)
last_trigger_index = text.rfind(trigger_str)
if last_trigger_index == -1:
return ""
next_end_index = text.find(end_str, last_trigger_index)
if next_end_index == -1:
return ""
substring = text[last_trigger_index + len(trigger_str):next_end_index]
return substring
def decode_object_name(object_name):
# Decode the object name from the URL-encoded format
return urllib.parse.unquote_plus(object_name)
# Function to get the image and turn it into a base64 string
def get_image_base64(bucket, key):
try:
response = s3.get_object(Bucket=bucket, Key=key)
except ClientError as e:
print(e)
return False
else:
image = response['Body'].read()
return image
def get_image_type(bucket, key):
# Get the Mime type using object key and head_object
# Must use head_object
try:
response = s3.head_object(Bucket=bucket, Key=key)
except ClientError as e:
print(e)
return False
else:
content_type = response['ContentType']
print(content_type)
return content_type
def generate_summary(image_base64, content_type):
# Generate a summary of the input image using the Bedrock Runtime and claude3 model
# Must usee invoke_model
prompt = """Your purpose is to catalog images based upon common categories.
Create a structured set of data in json providing a summary of the image and a very short, generalised, image category. Do not return any narrative language.
Before you provide any output, show your working in <scratchpad> XML tags.
JSON fields must be labelled image_summary and image_category.
Example json structure is:
<json>
{
"image_summary": SUMMARY OF THE IMAGE,
"image_category": SHORT CATEGORY OF THE IMAGE,
}
</json>
Examples of categorie are:
Animals
Nature
People
Travel
Food
Technology
Business
Education
Health
Sports
Arts
Fashion
Backgrounds
Concepts
Holidays
Output the json structure as a string in <json> XML tags. Do not return any narrative language.
Look at the images in detail, looking for people, animals, landmarks or features and where possible try to identify them.
"""
response = bedrock_runtime.invoke_model(
modelId='anthropic.claude-3-haiku-20240307-v1:0',
contentType='application/json',
accept='application/json',
body=json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 1000,
"system": prompt,
"messages": [
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "base64",
"media_type": content_type,
"data": image_base64
}
},
# {
# "type": "text",
# "text": prompt
# }
]
}
]
})
)
print(response)
return json.loads(response.get('body').read())
def store_summary(object_id, summary, category):
# Store the summary in DynamoDB
# Must use put_item
table = dynamodb.Table(IMAGE_TABLE)
table.put_item(
Item={
'id': object_id,
'summary': summary,
'category': category
}
)
def lambda_handler(event, context):
print(json.dumps(event, indent=4))
object_name = decode_object_name(event['Records'][0]['s3']['object']['key'])
image_type = get_image_type(IMAGE_BUCKET, object_name)
image_base64 = get_image_base64(IMAGE_BUCKET, object_name)
if not image_base64:
return {
'statusCode': 500,
'body': json.dumps('Error getting image')
}
else:
image_base64 = base64.b64encode(image_base64).decode('utf-8')
response_body = generate_summary(image_base64, image_type)
print(response_body)
summary = response_body['content'][0]['text']
json_summary = json.loads(extract_substring(summary, "<json>", "</json>"))
image_summary = json_summary['image_summary']
image_category = json_summary['image_category']
store_summary(object_name, image_summary, image_category)
return {
'statusCode': 200,
'body': json.dumps('Summary stored in DynamoDB')
}
NOTE: To call a bedrock-friendly version of boto3 we’re making use of a Lambda Layer. This must be built into your account before deploying this SAM template. You will then need to include the ARN of the layer as a Parameter as you deploy. To build the boto3 lambda layer:
Open Cloud Shell from the AWS Console and type the following commands
mkdir ./bedrock-layer
cd ./bedrock-layer
mkdir ./python
pip3 install -t ./python/ boto3
zip -r ../bedrock-layer.zip .
cd ..
aws lambda publish-layer-version \
--layer-name bedrock-layer \
--zip-file fileb://bedrock-layer.zip
Source:- https://www.linkedin.com/posts/mikegchambers_serverless-python-activity-7154258975926964224-IL4G
The Front End
To use the information we’ve generated in a useful way I created a very simple front end. This just lists any data in the dynamoDB and gives a thumbnail.
I’ve kept this as basic as possible. The hero of the story here after all is Claude… not my horrific javascript skills.
As you can see, Claude has done pretty well at creating a summary and categorising these images. This could then lead to further features being added such as search engines in large collections or services like Amazon Polly to explain what the image is.
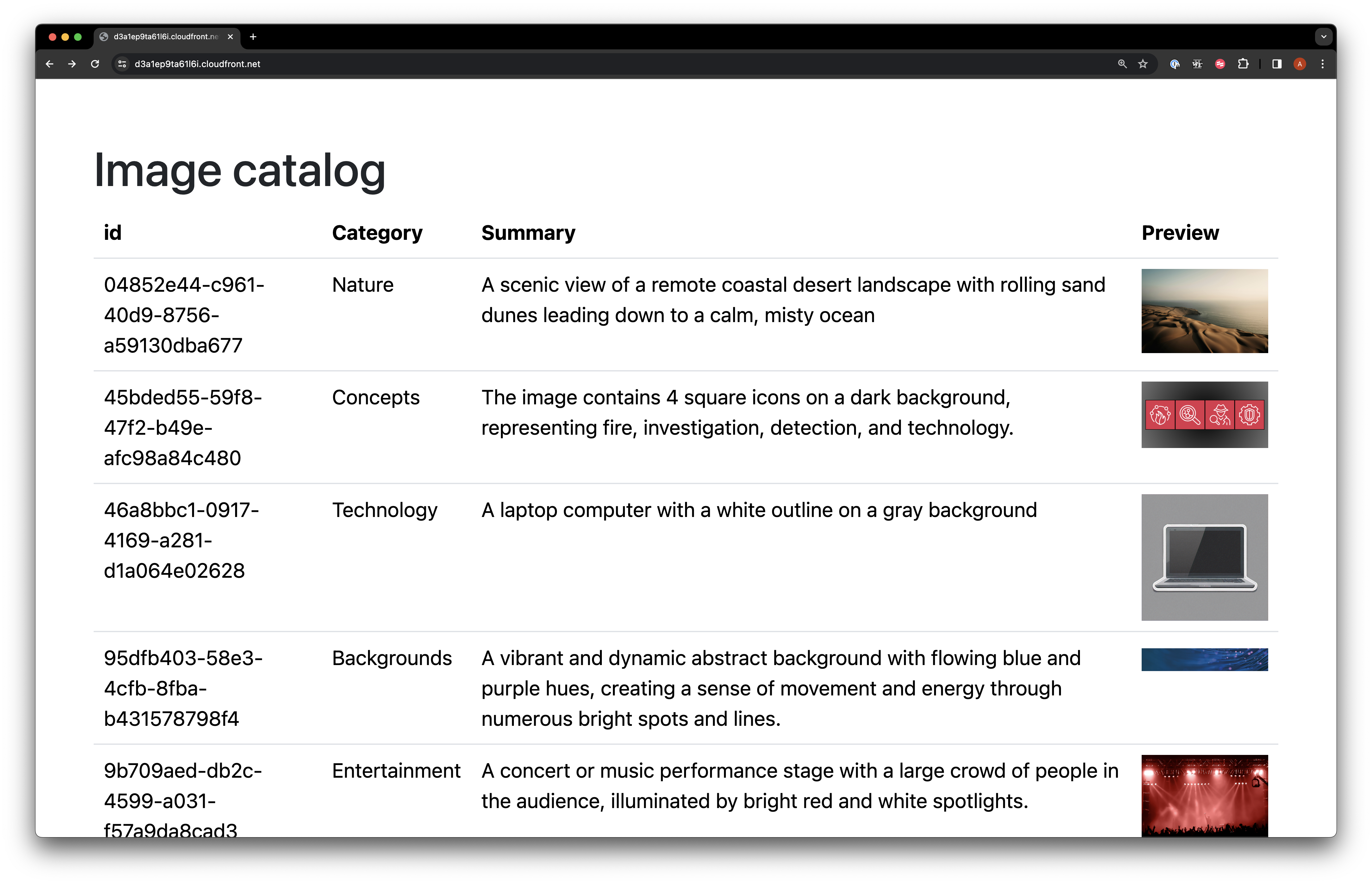
Imagine how good this would be at Pictionary!
The SAM Template
The glue that holds this all together is a SAM template defining the resources in a declarative language that we’re all familiar with.
I’ve kept this template as simple as possible, including a SimpleTable for the DynamoDB table and separating resources between the frontend and the backend.
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Description: >
AI Photo album
Globals:
Api:
Cors:
AllowMethods: "'*'"
AllowHeaders: "'*'"
AllowOrigin: "'*'"
AllowCredentials: "'*'"
Function:
Timeout: 30
MemorySize: 256
Runtime: python3.11
Environment:
Variables:
INCOMING_BUCKET: !Sub '${Prefix}-${Workload}-incoming'
IMAGE_BUCKET: !Sub '${Prefix}-${Workload}-images'
IMAGE_TABLE: !Ref ImageTable
Architectures:
- arm64
Parameters:
Prefix:
Type: String
Description: Prefix for all resources
Default: my-ml
Workload:
Type: String
Description: Workload of the application
Default: photo-album
BedrockLayerArn:
Type: String
Description: ARN of the Bedrock layer
Default: arn:aws:lambda:us-west-2:168420111683:layer:bedrock-layer:1
Resources:
### Backend resources
ImageTable:
Type: AWS::Serverless::SimpleTable
Properties:
PrimaryKey:
Name: id
Type: String
TableName: !Sub '${Prefix}-${Workload}-image-table'
IncomingBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Sub '${Prefix}-${Workload}-incoming'
AccessControl: Private
PublicAccessBlockConfiguration:
BlockPublicAcls: true
BlockPublicPolicy: true
IgnorePublicAcls: true
RestrictPublicBuckets: true
ImageBucket:
Type: AWS::S3::Bucket
Properties:
BucketName: !Sub '${Prefix}-${Workload}-images'
AccessControl: Private
PublicAccessBlockConfiguration:
BlockPublicAcls: true
BlockPublicPolicy: true
IgnorePublicAcls: true
RestrictPublicBuckets: true
RenameImageFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: rename_image/
Handler: app.lambda_handler
Layers:
- !Ref BedrockLayerArn
Policies:
- S3ReadPolicy:
BucketName: !Sub '${Prefix}-${Workload}-incoming'
- S3WritePolicy:
BucketName: !Sub '${Prefix}-${Workload}-images'
Events:
S3ObjectCreated:
Type: S3
Properties:
Bucket:
Ref: IncomingBucket
Events: s3:ObjectCreated:*
SummariseImageFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: summarise_image/
Handler: app.lambda_handler
Layers:
- !Ref BedrockLayerArn
Policies:
- DynamoDBWritePolicy:
TableName: !Ref ImageTable
- S3ReadPolicy:
BucketName: !Sub '${Prefix}-${Workload}-images'
- Statement:
- Sid: Bedrock
Effect: Allow
Action:
- bedrock:InvokeModel
Resource: !Sub 'arn:aws:bedrock:${AWS::Region}::foundation-model/*'
Events:
S3ObjectCreated:
Type: S3
Properties:
Bucket:
Ref: ImageBucket
Events: s3:ObjectCreated:*
GetImagesFunction:
Type: AWS::Serverless::Function
Properties:
CodeUri: get_images/
Handler: app.lambda_handler
Policies:
- DynamoDBReadPolicy:
TableName: !Ref ImageTable
Events:
Api:
Type: Api
Properties:
Path: /images
Method: get
### Front end resources
ImageHostingOriginaccessidentity:
Type: AWS::CloudFront::CloudFrontOriginAccessIdentity
Properties:
CloudFrontOriginAccessIdentityConfig:
Comment: !Sub ${Prefix}-${Workload}-originaccessidentity
ImageHostingBucketPolicy:
Type: AWS::S3::BucketPolicy
Properties:
Bucket: !Ref ImageBucket
PolicyDocument:
Statement:
-
Action:
- "s3:GetObject"
Effect: "Allow"
Resource:
Fn::Join:
- ""
-
- "arn:aws:s3:::"
-
Ref: ImageBucket
- "/*"
Principal:
CanonicalUser: !GetAtt ImageHostingOriginaccessidentity.S3CanonicalUserId
ImageHostingCloudFront:
Type: AWS::CloudFront::Distribution
Properties:
DistributionConfig:
Enabled: true
Comment: !Sub ${Prefix}-${Workload}-distribution
DefaultRootObject: index.html
CustomErrorResponses:
- ErrorCode: 400
ResponseCode: 200
ResponsePagePath: "/error.html"
- ErrorCode: 403
ResponseCode: 200
ResponsePagePath: "/error.html"
- ErrorCode: 404
ResponseCode: 200
ResponsePagePath: "/error.html"
Origins:
- Id: ImageBucket
DomainName: !Sub ${ImageBucket}.s3.${AWS::Region}.amazonaws.com
S3OriginConfig:
OriginAccessIdentity: !Join [ "", [ "origin-access-identity/cloudfront/", !Ref ImageHostingOriginaccessidentity ] ]
DefaultCacheBehavior:
TargetOriginId: ImageBucket
ViewerProtocolPolicy: redirect-to-https
Compress: false
CachePolicyId: "4135ea2d-6df8-44a3-9df3-4b5a84be39ad"
ResponseHeadersPolicyId: "5cc3b908-e619-4b99-88e5-2cf7f45965bd"
OriginRequestPolicyId: "88a5eaf4-2fd4-4709-b370-b4c650ea3fcf"
Summary
Some of the most important lessons I learned in this experience were not about Amazon Bedrock. Whilst I utilized Bedrock to call our new friend, Sir Claude the third of Haiku, I spent more time working on my prompt than I did calling Bedrock. Many iterations of this prompt happened and also varying changes between system prompts and multi-modal prompts (The ability to use images and text in a prompt).
As we conclude our exploration of Haiku and its role in our photo album application, we’re reminded of the boundless possibilities that AI and cloud computing offer in reshaping our digital landscape. I see this being used in many use cases but I can’t escape the ability to use this to make life easier who may be vision impaired:
A guided tour of an art museum Assistive technology when going through daily life such as shopping for groceries Advanced screen reading.
Some of these use cases can even lead to the betterment of social inclusion for people with disabilities and vision impairment.
There are many commercial use cases for Claude 3’s vision capabilities including and not limited to marketing, hospitality, healthcare/wellness and many more but I’ll leave these to your imagination, as the opportunities are endless.
What next?
Curious to explore the world of Claude 3 Haiku and its applications beyond photo management? Dive deeper into AWS services and AI technologies, and discover the endless possibilities of AI models in enriching our digital experiences. Share your thoughts and insights in the comments on my LinkedIn or below, and let’s embark on an AI journey together!