As developers, we’ve all encountered it: the dreaded task of writing documentation. Whether it’s explaining your own code or trying to understand someone else’s, a lack of clear documentation can be a major headache. Often, we spend hours deciphering code when we could be writing new features or fixing bugs.

It’s not a chatbot
For those of you who follow my various mediums, you’ll have noticed a recurring theme in my content over the last three months: “It’s not a chatbot!” This seems to be becoming a series in its own right. I endeavor to advocate for Generative AI use cases without showcasing a chatbot.
If you haven’t followed my previous works, here are some links to catch up:
As a developer, have you ever written an application or script and then been asked to document it? Or read someone else’s code and wished it had better documentation? This is a common frustration shared by developers.
Cue our heros, Claude and Converse API
“Oh my! It’s Sir Claude the Third!”
I saw this as an opportunity to test out the latest Bedrock feature, Converse API with Claude 3 Haiku. I wanted to create something independent of any architecture, so no serverless lambda functions or API gateways in this example. Just the ability to:
- Run from a command line
- Apply to pipelines like GitHub Actions
- Be portable to run anywhere
“Amazon Bedrock announces the new Converse API, which provides developers a consistent way to invoke Amazon Bedrock models removing the complexity to adjust for model-specific differences such as inference parameters” - Amazon Bedrock announces new Converse API - AWS
Converse API vs Invoke Model
As the AWS blog post suggests, Converse API is designed to reduce the complexity of invoking a machine learning model, making it even quicker and easier to write code with Bedrock. In fact, here is my Converse API call:
1
2
3
4
5
6
7
| response = bedrock_runtime.converse(
modelId=model_id,
messages=[messages],
system=system_prompt,
inferenceConfig=inference_config,
additionalModelRequestFields=additional_model_fields
)
|
Compare this with a similar invoke_model prompt:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| response = bedrock_runtime.invoke_model(
modelId='anthropic.claude-3-haiku-20240307-v1:0',
contentType='application/json',
accept='application/json',
body=json.dumps({
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 1000,
"system": system_prompt,
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt
}
]
}
]
})
)
|
While I’ve used a few variables in the Converse API call, even with variables, the invoke_model call looks fairly ugly and hard to decipher.
Prompt Engineering
So, as with all good Generative AI projects, we need a good prompt first. I’ve learned a fair bit about Prompt Engineering recently, so let me remind you of my top tips:
- Keep your prompt simple but concise.
- Treat it like you’re training someone to do something for the first time.
- Give the model a purpose.
- Let it think.
- Structure your output.
In this case, I’m going to use a system prompt (below) to tell the model what its purpose is and then hand it the source code in a text prompt.
1
2
3
4
5
6
7
8
9
| You are a technical writer tasked with documenting the provided source code. Your goal is to create documentation that is easily understood by individuals of varying technical expertise and business backgrounds. The documentation should be written in plain English, with source references included where applicable.
Requirements:
The documentation must have a title and a subtitle.
Use code formatting where relevant.
Format the documentation in markup language suitable for a .md (Markdown) file.
Output your thought process within <scratchpad> XML tags. Output your final documentation within <markup> XML tags.
|
I then construct the rest of my Converse API call, applying some simple configuration.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| message = {
"role" : "user",
"content" : [
{
"text" : source
}
]
}
inference_config = {"temperature": 0.5}
additional_model_fields = {"top_k": 200}
response = bedrock_runtime.converse(
modelId=model_id,
messages=[messages],
system=system_prompt,
inferenceConfig=inference_config,
additionalModelRequestFields=additional_model_fields
)
|
“Is that it?”
Yep, that’s it. The rest of the complexity comes down to how I want to read the output and store it later.
1
2
| output = response['output']['message']['content'][0]['text']
markup_output = extract_substring(output, "<markup>","</markup>")
|
Once I’ve extracted the content from the markup tags, I store it in a file.
And there we have it: using the source for this entire script to document itself, from source to docs, as shown below:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
| import os
import sys
import json
import boto3
from botocore.config import Config
region_config = Config(
region_name="ap-southeast-2"
)
bedrock_runtime = boto3.client("bedrock-runtime", config=region_config)
model_id = "anthropic.claude-3-haiku-20240307-v1:0"
temp = 0.5
top_k = 200
def init(output_dir):
# Output the current meta data including boto3 version, aws account id and region.
print(boto3.client('sts').get_caller_identity().get('Account'))
print(boto3.client('sts').meta.region_name)
print(boto3.__version__)
# if docs/ directory does not exist, create it.
if not os.path.exists(output_dir):
os.makedirs(output_dir)
def extract_substring(text, trigger_str, end_str):
last_trigger_index = text.rfind(trigger_str)
if last_trigger_index == -1:
return ""
next_end_index = text.find(end_str, last_trigger_index)
if next_end_index == -1:
return ""
substring = text[last_trigger_index + len(trigger_str):next_end_index]
return substring
def ingest(filename):
with open(filename, 'r') as f:
return f.read()
def write_output(markup_output, output_file):
with open(output_file, 'w') as f:
f.write(markup_output)
f.close()
def main(source_file, output):
source = ingest(source_file)
system_prompt = [
{
"text" : """
You are a technical writer tasked with documenting the provided source code. Your goal is to create documentation that is easily understood by individuals of varying technical expertise and business backgrounds. The documentation should be written in plain English, with source references included where applicable.
Requirements:
The documentation must have a title and a subtitle.
Use code formatting where relevant.
Format the documentation in markup language suitable for a .md (Markdown) file.
Output your thought process within <scratchpad> XML tags. Output your final documentation within <markup> XML tags.
"""
}
]
message = {
"role" : "user",
"content" : [
{
"text" : source
}
]
}
messages = [message]
inference_config = {"temperature": temp}
additional_model_fields = {"top_k": top_k}
response = bedrock_runtime.converse(
modelId=model_id,
messages=messages,
system=system_prompt,
inferenceConfig=inference_config,
additionalModelRequestFields=additional_model_fields
)
output = response['output']['message']['content'][0]['text']
markup_output = extract_substring(output, "<markup>","</markup>")
# Output markup_output into a file
function_name = os.path.dirname(source_file)
output_file = os.path.join(output_dir, f"{function_name}.md")
write_output(markup_output, output_file)
if __name__ == "__main__":
if len(sys.argv) != 3:
print("Usage: python generate_docs.py <source_file> <output_dir>")
sys.exit(1)
source_file = sys.argv[1]
output_dir = sys.argv[2]
init(output_dir)
main(source_file, output_dir)
|
To this in Markdown;
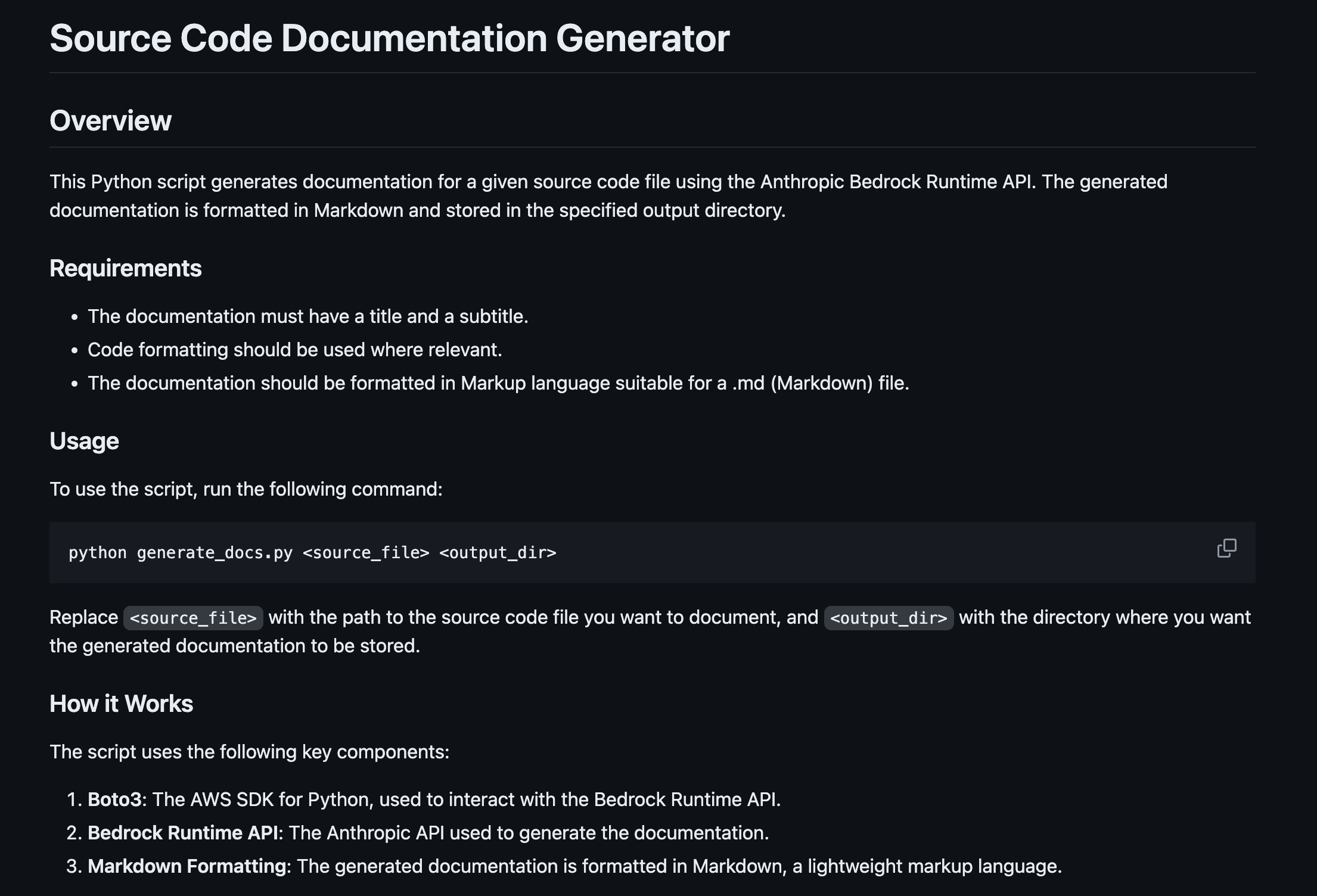
This code can now be run from my laptop as I write new code or applied to GitHub Actions or AWS CodePipeline when I deploy new code, it’ll automatically document itself!
If you want to play with this then feel free to check out the repo below. I’ve made some code samples and generated documentation as well available
Resources
