
Scan vs Query in DynamoDB: Stop Wasting Read Capacity Units
Let’s talk about one of the most common (and costly) mistakes I see in serverless applications using Amazon DynamoDB: overusing `Scan` when a `Query` would do the job better — faster, cheaper, and more predictably.
Let’s talk about one of the most common (and costly) mistakes I see in serverless applications using Amazon DynamoDB: overusing Scan when a Query would do the job better — faster, cheaper, and more predictably.
“The ‘scan is easier and we don’t need indexes’ anti pattern

This came up in a recent Lambda function I reviewed, which was fetching user data from the compendium_users table. It used a Scan and filtered with Attr(). Functional, but inefficient. Once traffic started to ramp up, it became obvious I needed a better approach.
So I decided to introduce a Global Secondary Index (GSI) on the user_key attribute and switched the logic to use a Query instead.
Understanding the Schema
Here’s what a typical compendium_users record looks like:
| |
This schema was migrated from a relational database that auto incremented primary keys. Validating a user would generally be something like SELECT * FROM users WHERE user_key = '9a7219de-0444-49cd-a804-8ab38a794f21'. In fact it was rare that I used the user_id, it was just convenient for our internal systems to auto generate the primary key to ensure it was always unique.
In this newly migrated schema, user_id is the primary key, but our Lambda function needed to look up users by user_key — a UUID that is treated as the external-facing identifier. Since user_key is not the primary key, a Query operation wouldn’t work out of the box.
FYI: The data was migrated using AWS Data Migration Service (DMS).
That’s where the Global Secondary Index (GSI) came in. I created a GSI with user_key as the partition key, which allowed me to switch from Scan + FilterExpression to a highly efficient Query on the GSI.
If you find yourself in the same position — needing to search on a non-key attribute — this is exactly what GSIs are designed for.
The Before and After
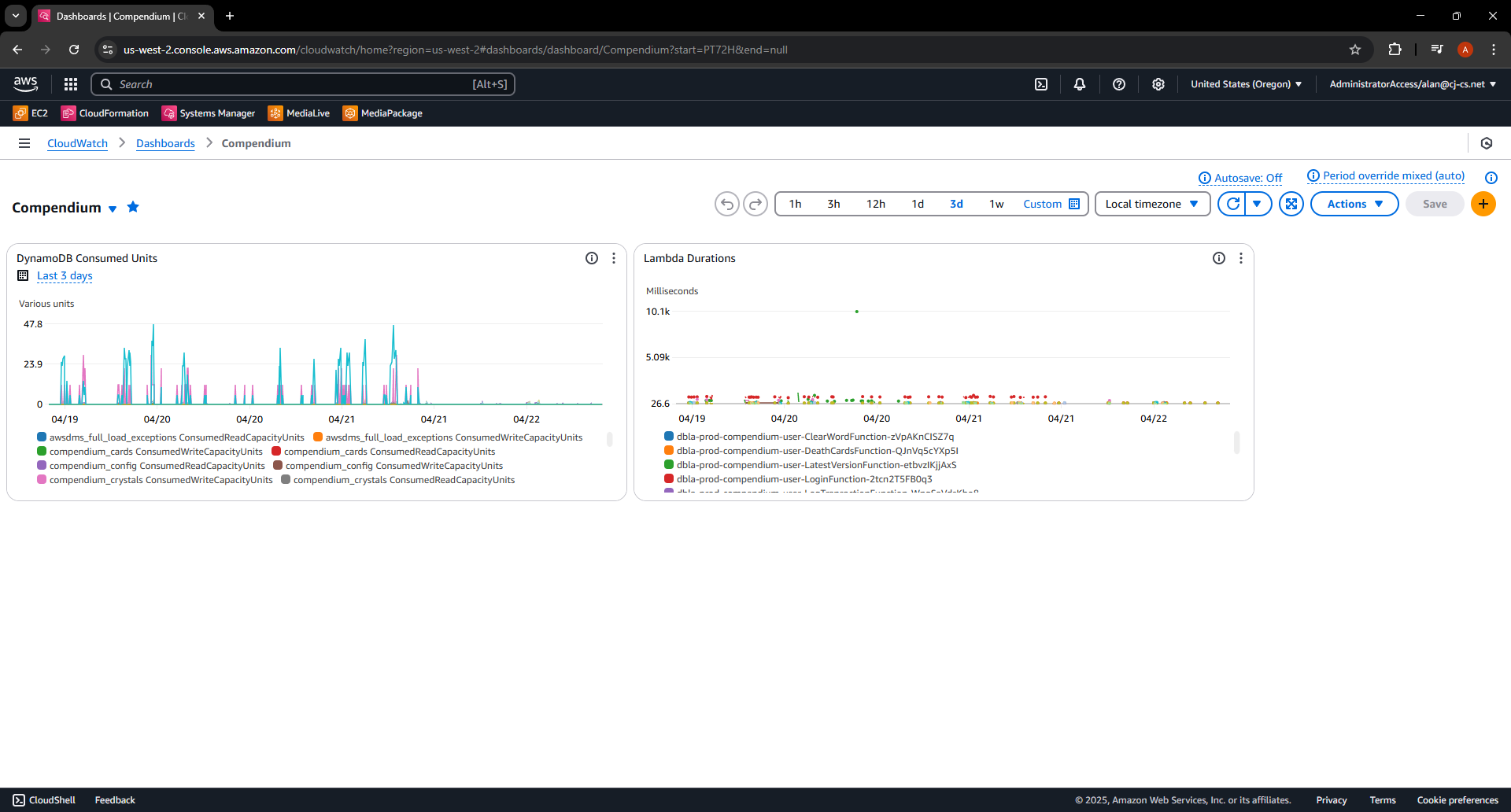
The change was deployed on Saturday, April 19, 2025 at 11:35 PM AEST. Within minutes, I saw:
- 42+ fewer RCUs consumed per read from
compendium_users - Slight improvement in Lambda duration due to faster data access
This is not theoretical or hypothetical — I validated this improvements in performance directly from CloudWatch metrics and billing data. A small change, big payoff.
Scan: the Anti-Pattern
Using Scan in production is a DynamoDB anti-pattern. It reads every item in your table, then filters results after retrieval. You’re paying for every item read, even if you only need one.
This is fine during prototyping, but in real workloads, it becomes a scalability bottleneck — and a silent cost amplifier.
Example:
| |
Query: the Right Tool
Query is laser-focused. It reads only the items that match your keys. When you combine it with a GSI, you can support alternative access patterns without restructuring your table.
Example:
| |
Scan is a Symptom
If you’re reaching for Scan, it’s usually a sign of one of two things:
- Your data model doesn’t align with your access patterns.
- You’re missing an index.
Both are solvable. A GSI might introduce a small write cost, but it saves you much more in read performance and application responsiveness.
TL;DR
- Scan is an anti-pattern in production: inefficient and unscalable.
- Query is your friend when used with the right keys or indexes.
- Use GSIs to support non-primary-key access patterns.
- Always design DynamoDB tables based on your read patterns, not just your entities.
This optimization cost me one index and a couple lines of code — and gave me immediate, measurable results.
Need help spotting anti-patterns in your own serverless stack? Happy to share examples and battle scars.